
By Daniel Durling (Senior Data Scientist)
In Part 1 of our Text Analysis blog series, we talked about how you could start to analyse the free text you already have stored in your database/data warehouse. In Text Analysis Part 2, we take this a step further, discussing how you could use some more advanced techniques to make the most of your text analysis.
Today’s blog will look at:
- Stemming
- lemmatisation
- Sentiment analysis
- Levenstien distance
- Zipf law
- Word2vec
Getting data for my examples
As before in Text Analysis part one, in Text Analaysis part 2 I will be using copyright-free eBooks accessible as part of project Guttenberg and I will be using the programming language R for consistency. Also, for consistency, I shall use the free ebooks we have already looked at; the Dunwich horror and don Quixote.
So let us get that data again, first, let’s load some packages:
library(tidyverse) library(tidytext) library(gutenbergr)
Then get and clean data for the dunwich horror:
the_dunwich_horror <- gutenberg_download(50133,
meta_fields = c("title", "author"),
verbose = FALSE)
the_dunwich_horror_clean <- the_dunwich_horror %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text,
regex("^[:digit:]+$",
ignore_case = TRUE))))
the_dunwich_horror_clean %>%
unnest_tokens(word, text) %>%
count(word, sort = TRUE)
the_dunwich_horror_clean %>%
unnest_tokens(word, text) %>%
anti_join(stop_words, by = "word") %>%
count(word, sort = TRUE)
And then let’s do the same for Don Quioxte:
don_quioxte <- gutenberg_download(996,
meta_fields = c("title", "author"),
verbose = FALSE)
don_quioxte_clean <- don_quioxte %>%
mutate(linenumber = row_number(),
chapter = cumsum(str_detect(text,
regex("^chapter [\\divxlc]{1,}\\.$",
ignore_case = TRUE))))
Ok, now we once again have our data, let’s look at how we can extract further meaning from it.
Stemming
You will remember from part 1 (link) that when we looked at the TF-IDF score, we saw in our visualisation that whaterleys & whaterley’ both appear as words with a high TF-IDF score for the Dunwich Horror.
Lemmatisation
Lemmatisation can be thought of as a more nuanced version of stemming. Whereas Stemming reduces words to their “stem” – lemmatisation gets us to the root of the word (even if the root word is a different word entirely).
Sentiment Analysis
Sentiment analysis is the computational analysis of text to understand the sentiment contained within it. When a human reads a text, we combine what is being said in the words, sentences, and paragraphs to understand if what we are reading is positive or negative. Through sentiment analysis we try to do this computationally.
We do this by looking at every word in a corpus and assigning it a numerical score based on its sentiment. We can score this in different ways, such as the AFINN lexicon (which scores words on a -5 to 5 scale for negative to positive) or the Bing lexicon which categorises words as a binary TRUE/FALSE for Positive or Negative words.
The scores can be looked up online or can be consulted within R by using the following code:
get_sentiments("afinn")
get_sentiments("bing")
Now, how can we use this to show how sentiment builds throughout a story? Well, let’s look at the sentiment scores for the HP Lovecraft story:
the_dunwich_horror_clean %>%
unnest_tokens(word, text) %>%
inner_join(get_sentiments("bing")) %>%
group_by(chapter) %>%
count(sentiment) %>%
pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(sentiment = positive - negative) %>%
ggplot(aes(chapter, sentiment)) +
geom_col() +
scale_x_discrete() +
theme_bw()
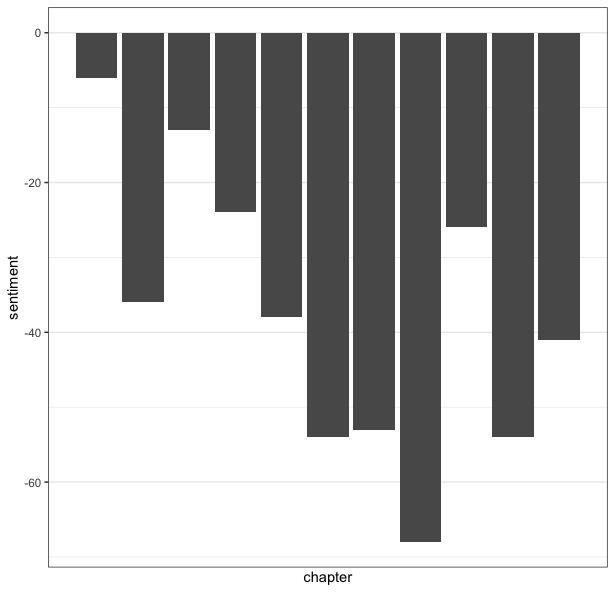
As you might have expected, the sentiment of a horror story is rather negative throughout, building throughout the story before a slight reprieve, before continuing to its conclusion.
In the world of work, sentiment analysis is useful for quickly understanding if the text you are analysis (perhaps a review) is negative or positive, and then based on the sentiment score you might perform different business processes (if positive, send thank you email with discount code, if negative, try to reach out for more information and see if it is possible to address the issues raised).
Conclusion
So, there we have it, some more advanced techniques you might now have been aware of to help you get a better understanding of data you already have. Now you know some of what is possible with your text analysis.
Now you know that analysis of a text is possible, let this feed into how you think about text information in the future, from how you design customer feedback forms to how you can analyse documents which previously had only been read by a human.
Want to chat more about free text? Send us a message here or follow us on social media here.