
By Dave Poole – Principal Data Engineer
Background
At synvert TCM (formerly Crimson Macaw) we ask ourselves “How we can deliver value to our customers at ever increasing pace”?
A challenge for our data engineers is that we must be able to cope with data that is in many different formats. To name but a few
- Avro
- CSV (and variations)
- Excel (both the long obsolete XLS and 15 years old XLSX format)
- Fixed width text
- JSON
- ORC / Parquet
- XML
To allow our data scientists to show their full value the data that we data engineers process must be available to the data scientists in a readily usable state.
“Readily usable” does not mean that data has been thrown over the wall and we make sure someone hears the splash as it lands in the data lake. There is no automagical tool that will allow for such behaviour.
A dimensional data model scores highly for ease of use. However, as a product of careful, “big picture” thinking with attention to detail, it does require an upfront investment in time. This investment will pay in the medium to long term though few businesses are prepared to wait. They want data to show business value much sooner.
What makes data usable?
Information about the schema of the data being received would be a big step forward. It allows data scientists to know what they are dealing with. However, a substantial percentage of data is in forms that are considered schema-less.
- CSV and TXT files have no explicit data types.
- Excel has number and text unless you are an Office 365 user
For JSON documents there is at least json-schema.org. This provides us with the following values for its “type” attribute.
- string
- integer
- number
- boolean
- null
- object
- array
The latter two are container types that allow repeating data structure definition.
Its format attribute allows us to see strings as other types such as date-time, UUID, IPV4 and others.
There are attributes that allow us to specify bounds and patterns to be used as validation parameters.
Title and description attributes allow us to tag business descriptions to properties in the schema.
How does Json-schema help us with CSV, Text, and Excel documents?
Consider the diagram below.
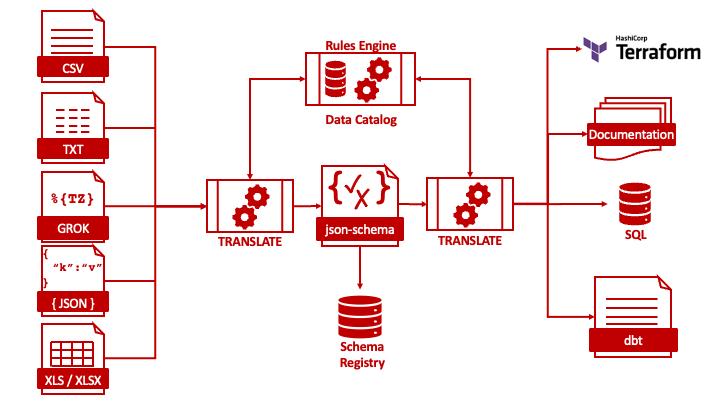
From the point of view of a schema, we could consider text files, CSV, Grok or fixed width, to be a tabular data structure. As such it is analogous to a flat JSON file. With data profiling, we can infer the more granular data types, validation patterns and bounds.
For the use of Excel format for data transfer, the challenge is that an Excel workbook or even an Excel worksheet can contain multiple tables. We can think of an Excel workbook as an array of data tables.
To the inferred schema we can add detail using a rules engine and a data catalogue. An example of that detail would be applying standard business descriptions to attributes and/or known data validation parameters.
By standardising on json-schema.org vocabulary to describe data structures we have a common data source for an application whose code is used to write other application code. That auto-generated code could be SQL CREATE statements, Python data classes, Terraform modules and even business-facing documentation.
Why not choose XML to represent schemas?
XML has XSD (XML Schema Definition) as a W3C standard. Just as we consider the schemas for tabular formats (CSV, TXT and Excel) to be flat JSON schemas we could argue the same for XSD.
The json-schema.org vocabulary is sufficient to represent the text data sources described here. One of the criticisms of XSD is that it is too complicated. If most of our data sources were XML then we would have chosen to standardise on XSD. However, many web systems have settled on a JSON-based message format.
json-schema.org vocabulary: Concluding thoughts
Code that generates code (meta-programming) produces code that follows a consistent pattern. We have found it far easier to read and debug code that follows a consistent pattern. Once a bug is found then fixing the code generator will fix all code generated from then on. If anything, consistency is more valuable, overall, than raw speed.
Auto-generative code buys us time to think about what the next value add activity may be rather than being too swamped by manual tasks to think beyond today.
Want to know more? Get in touch with us here.